Countdown Counter | Timer
|
nedtelling | counter | timer Verktøy!
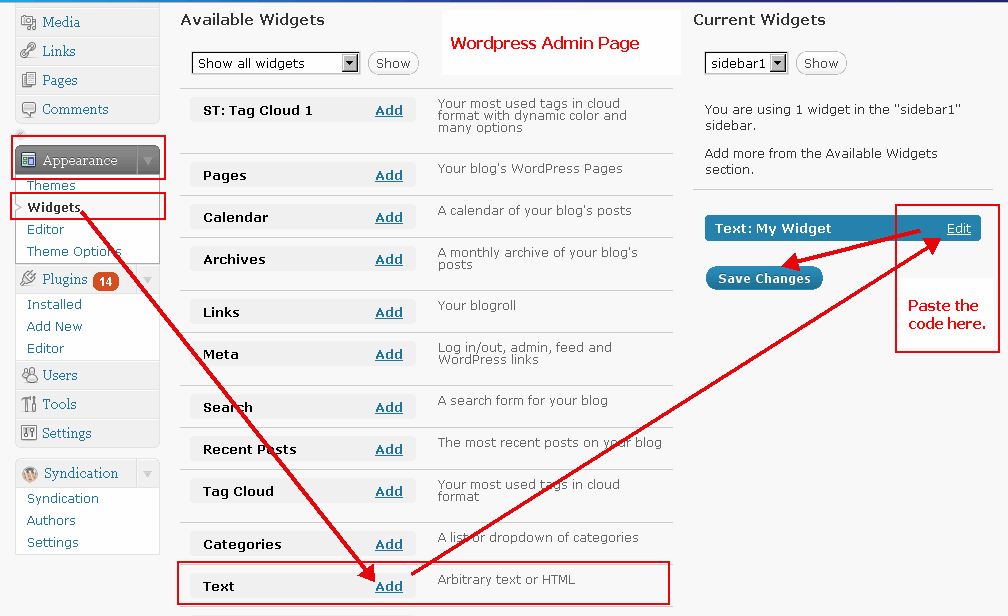
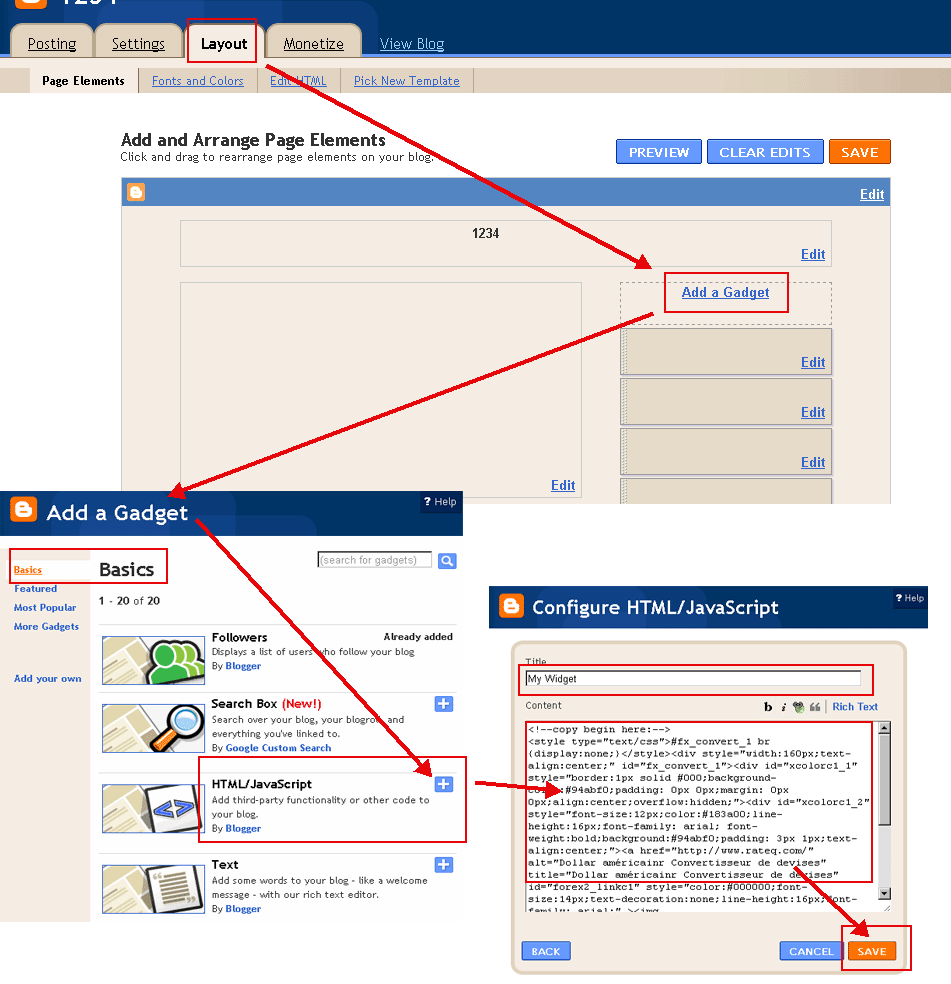
Trykk på knappen kopiere og lime inn i din blogg eller nettside. (Du kan bytte til HTML-modus når du legger inn i bloggen din. Eksempler: WordPress Eksempel, Blogger Eksempel) |
Bryllup Informasjon og nyheter |
{kind=link}
{kind=link}